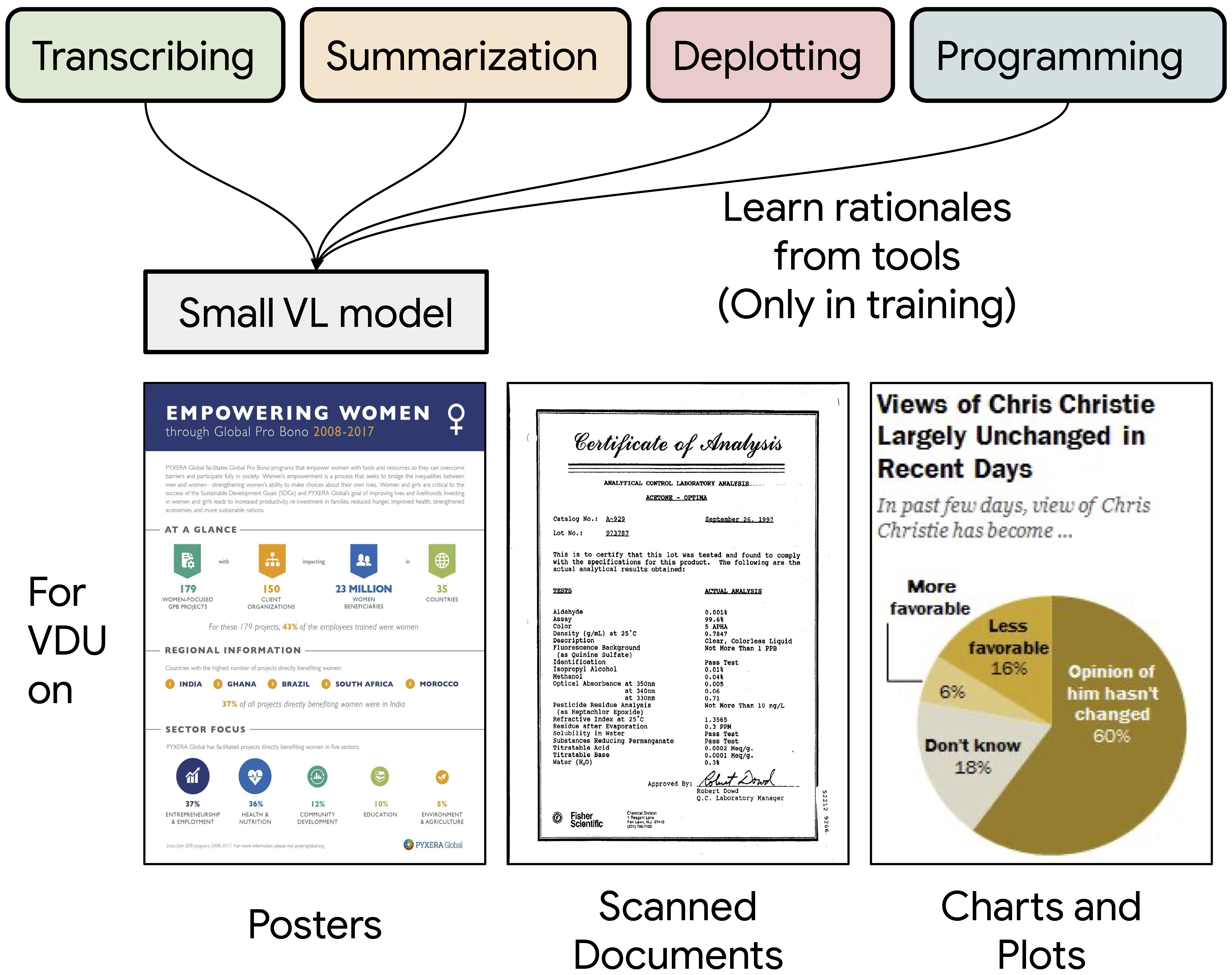
Understanding visually situated language requires interpreting complex layouts of textual and visual elements. Pre-processing tools, such as optical character recognition (OCR), can map document image inputs to textual tokens, then large language models (LLMs) can reason over text. However, such methods have high computational and engineering complexity. Can small pretrained image-to-text models accurately understand visual documents through similar recognition and reasoning steps instead? We propose Rationale Distillation (RD), which incorporates the outputs of OCR tools, LLMs, and larger multimodal models as intermediate "rationales", and trains a small student model to predict both rationales and answers. On three visual document understanding benchmarks representing infographics, scanned documents, and figures, our Pix2Struct (282M parameters) student model finetuned with RD outperforms the base model by 4-5% absolute accuracy with only 1% higher computational cost.
We first describe the process of generating the two types of rationales from tools, and a data augmentation scheme for increasing the number of examples with rationales.
Then, we discuss training and inference for student models to predict the rationale and the answer.
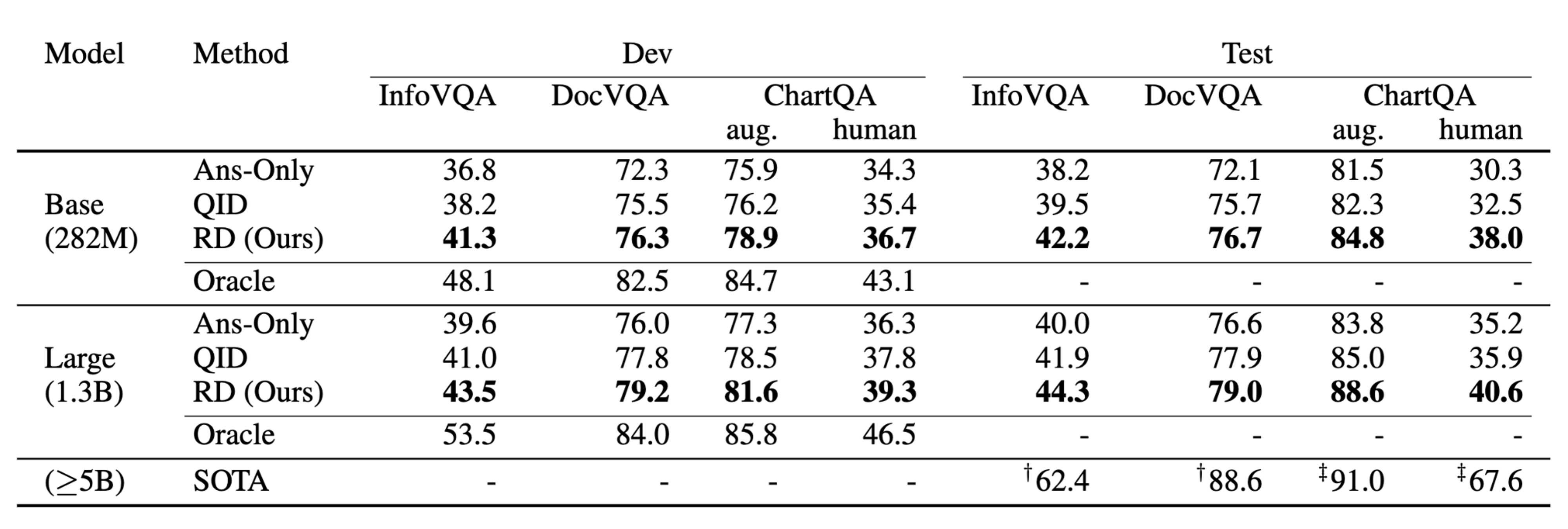
RD shows consistent improvements on InfoVQA (+4.0), DocVQA (+4.6) and ChartQA-human (+7.7) test sets, for the base Pix2Struct models. Similar improvements hold also on large Pix2Struct models.
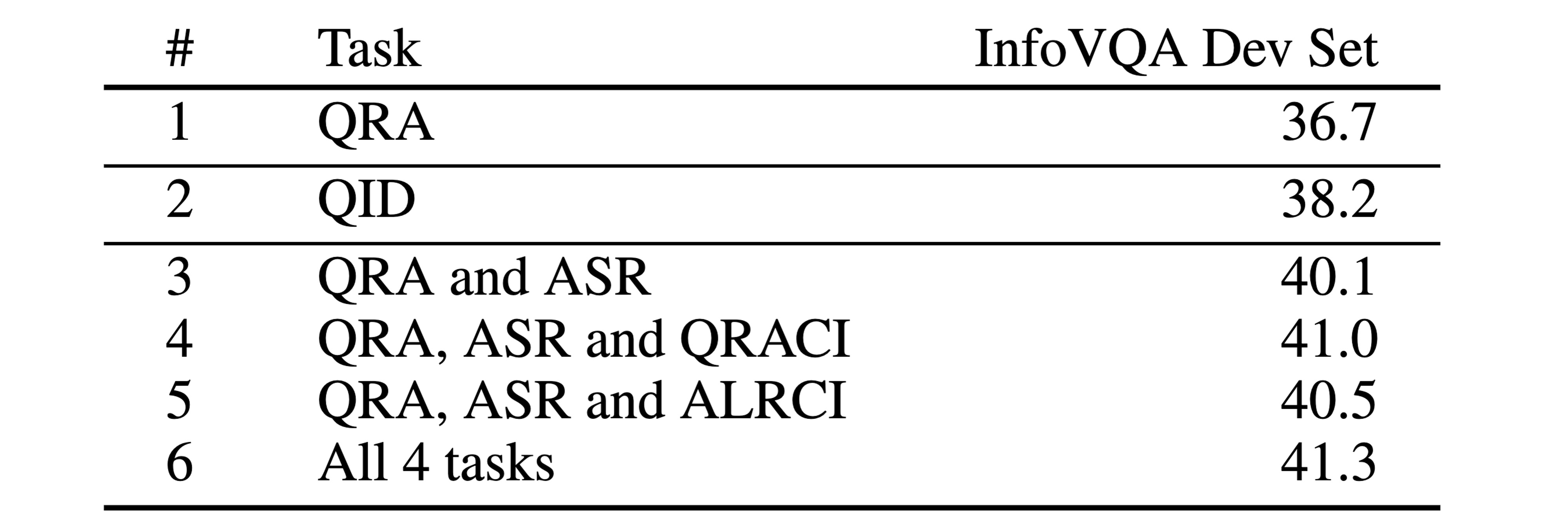
We conduct ablation study of different student training task combinations on the InfoVQA dev set: Question, Rationale and Answer (QRA), Answer with Student Rationale (ASR) and analogous tasks on Cropped Images (CI). We show the importance of both training to predict the gold rationales and training to predict the answer based on the noisy rationales (row #3), as well as the usefulness of image cropping augmentation (row #6).
We analyze the usefulness of the student-generated rationale in comparison to evidence from the OCR tool and several ways to sub-select fragments of similar length from it including LLM-Summarizer without access to gold answer (based on PaLM 2-L) We see that an external OCR tool would still provide benefits at the cost of added computation by the OCR system. Besides, the analysis indicates a large room for improvement in rationale prediction for student models.
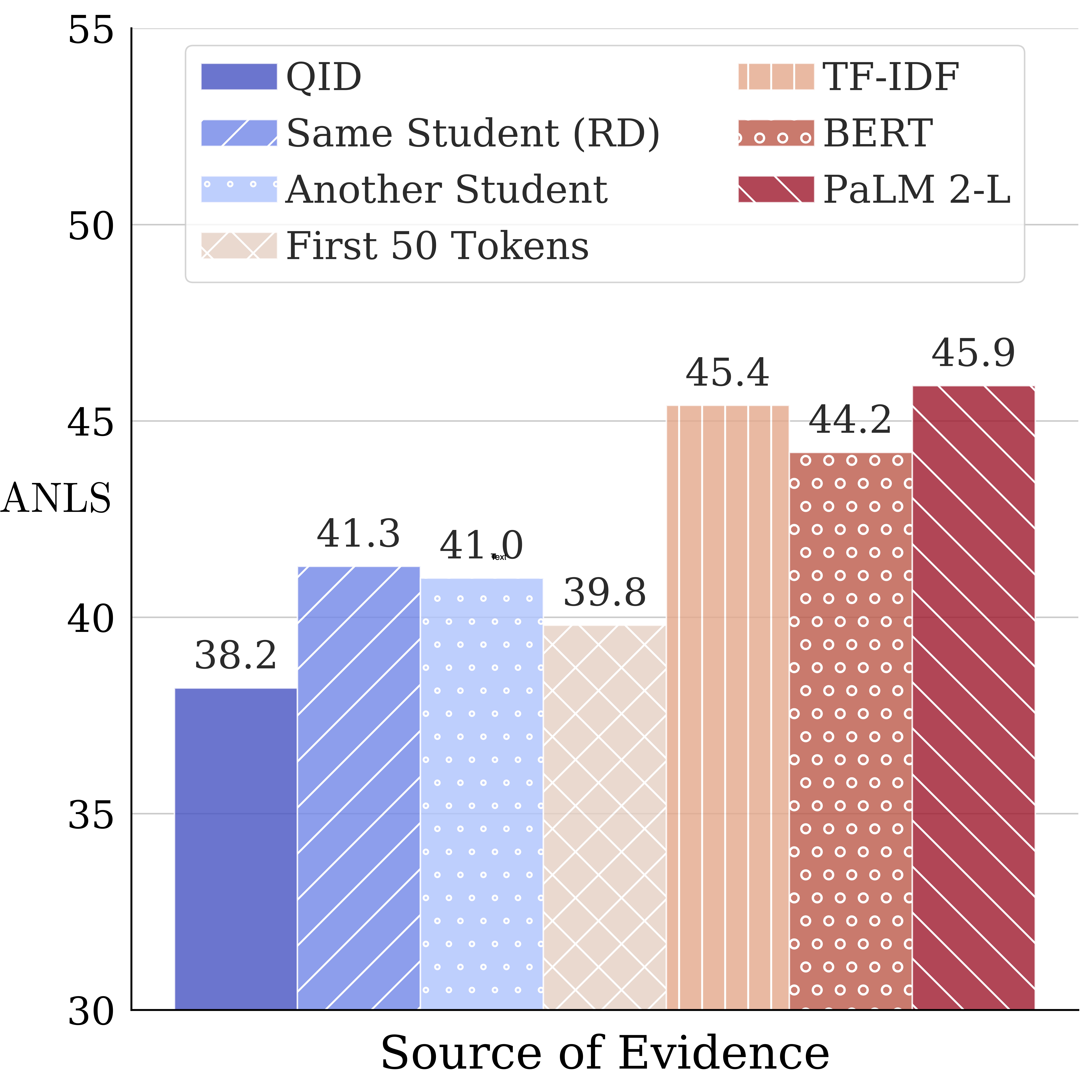
We observe large improvements when answers are text spans in the image or in the question. The former type indicates the helpfulness of the intermediate rationales; the latter suggests the helpfulness of decoding the question before answering.

@inproceedings{zhu2024efficient,
title={Efficient End-to-End Visual Document Understanding with Rationale Distillation},
author={Wang Zhu and Alekh Agarwal and Mandar Joshi and Robin Jia and Jesse Thomason and Kristina Toutanova},
booktitle = {North American Chapter of the Association for Computational Linguistics},
year={2024},
}